
硬盘SMART检测参数详解[转]
一、SMART概述
要说Linux用户最不愿意看到的事情,莫过于在毫无警告的情况下发现硬盘崩溃了。诸如RAID的备份和存储技术可以在任何时候帮用户恢复数据,但为预防硬件崩溃造成数据丢失所花费的代价却是相当可观的,特别是在用户从来没有提前考虑过在这些情况下的应对措施时。
硬盘的故障一般分为两种:可预测的(predictable)和不可预测的(unpredictable)。后者偶而会发生,也没有办法去预防它,例如芯片突然失效,机械撞击等。但像电机轴承磨损、盘片磁介质性能下降等都属于可预测的情况,可以在在几天甚至几星期前就发现这种不正常的现象。
对于可预测的情况,如果能通过磁盘监控技术,通过测量硬盘的几个重要的安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全”或“不久后会发生故障”。那么在发生故障前,至少有足够的时间让使用者把重要资料转移到其它储存设备上。
最早期的硬盘监控技术起源于1992年,IBM在AS/400计算机的IBM 0662 SCSI 2代硬盘驱动器中使用了后来被命名为Predictive Failure Analysis(故障预警分析技术)的监控技术,它是通过在固件中测量几个重要的硬盘安全参数和评估他们的情况,然后由监控软件得出两种结果:“硬盘安全”或“不久后会发生故障”。
不久,当时的微机制造商康柏和硬盘制造商希捷、昆腾以及康纳共同提出了名为IntelliSafe的类似技术。通过该技术,硬盘可以测量自身的的健康指标并将参量值传送给操作系统和用户的监控软件中,每个硬盘生产商有权决定哪些指标需要被监控以及设定它们的安全阈值。
1995年,康柏公司将该技术方案提交到Small Form Factor(SFF)委员会进行标准化,该方案得到IBM、希捷、昆腾、康纳和西部数据的支持,1996年6月进行了1.3版的修正,正式更名为S.M.A.R.T.(Self-Monitoring Analysis And Reporting Technology),全称就是“自我检测分析与报告技术”,成为一种自动监控硬盘驱动器完好状况和报告潜在问题的技术标准。
SMART的目的是监控硬盘的可靠性、预测磁盘故障和执行各种类型的磁盘自检。如今大部分的ATA/SATA、SCSI/SAS和固态硬盘都搭载内置的SMART系统。作为行业规范,SMART规定了硬盘制造厂商应遵循的标准,满足SMART标准的条件主要包括:
- 在设备制造期间完成SMART需要的各项参数、属性的设定;
- 在特定系统平台下,能够正常使用SMART;通过BIOS检测,能够识别设备是否支持SMART并可显示相关信息,而且能辨别有效和失效的SMART信息;
- 允许用户自由开启和关闭SMART功能;
- 在用户使用过程中,能提供SMART的各项有效信息,确定设备的工作状态,并能发出相应的修正指令或警告。在硬盘及操作系统都支持SMART技术并且开启的情况下,若硬盘状态不良,SMART功能会在开机时响起警报,SMART技术能够在屏幕上显示英文警告信息:“WARNING IMMEDIATLY BACKUP YOUR DATA AND REPLACE YOUR HARD DISK DRIVE,A FAILURE MAY BE IMMINENT.”(警告:立刻备份你的数据并更换硬盘,硬盘可能失效。)
SMART功能不断从硬盘上的各个传感器收集信息,并把信息保存在硬盘的系统保留区(service area)内,这个区域一般位于硬盘0物理面的最前面几十个物理磁道,由厂商写入相关的内部管理程序。这里除了SMART信息表外还包括低级格式化程序、加密解密程序、自监控程序、自动修复程序等。用户使用的监测软件通过名为“SMART Return Status”的命令(命令代码为:B0h)对SMART信息进行读取,且不允许最终用户对信息进行修改。
二、SMART信息解读
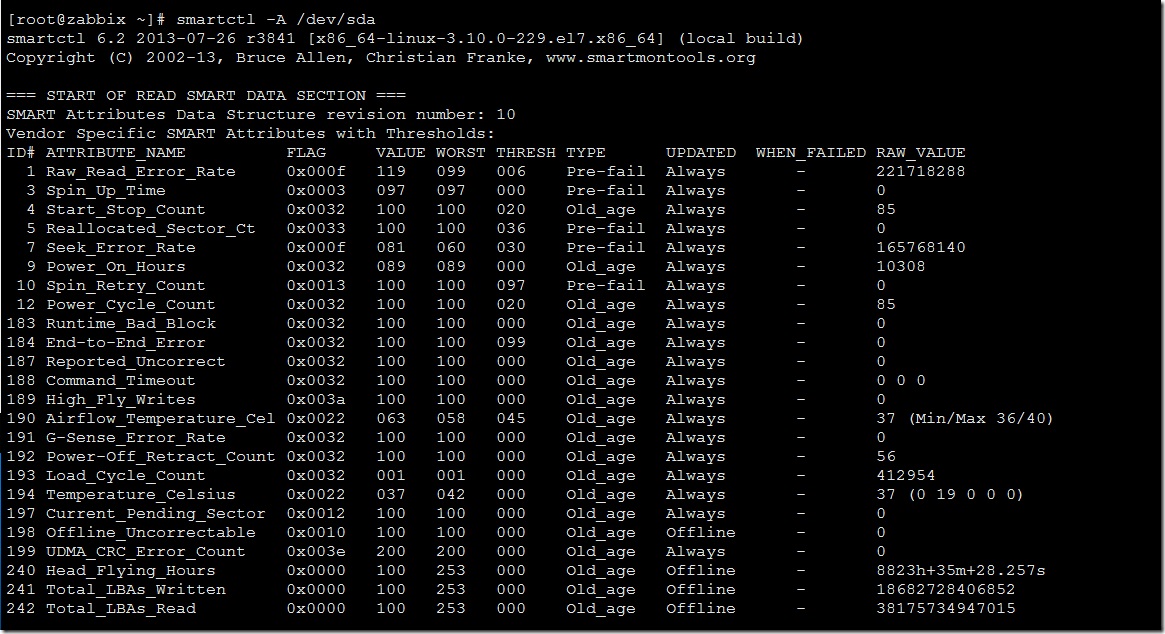 linux下执行命令smartctl -A /dev/sdx查看
linux下执行命令smartctl -A /dev/sdx查看
- ID
属性ID,通常是一个1到255之间的十进制或十六进制的数字。硬盘SMART检测的ID代码以两位十六进制数表示(括号里对应的是十进制数)硬盘的各项检测参数。目前,各硬盘制造商的绝大部分SMART ID代码所代表的参数含义是一致的,但厂商也可以根据需要使用不同的ID代码,或者根据检测项目的多少增减ID代码。一般来说,以下这些检测项是必需的:
01(001) Raw_Read_Error_Rate 底层数据读取错误率
04(004) Start_Stop_Count 启动/停止计数
05(005) Reallocated_Sector_Ct 重映射扇区数
09(009) Power_On_Hours 通电时间累计,出厂后通电的总时间,一般磁盘寿命三万小时
0A(010) Spin_Retry_Count 主轴起旋重试次数(即硬盘主轴电机启动重试次数)
0B(011) Calibration_Retry_Count 磁盘校准重试次数
0C(012) Power_Cycle_Count 磁盘通电次数
C2(194) Temperature_Celsius 温度
C7(199) UDMA_CRC_Error_Count 奇偶校验错误率
C8(200) Write_Error_Rate: 写错误率
F1(241) Total_LBAs_Written:表示磁盘自出厂总共写入的的数据,单位是LBAS=512Byte
F2(242) Total_LBAs_Read:表示磁盘自出厂总共读取的数据,单位是LBAS=512Byte
- ATTRIBUTE_NAME
硬盘制造商定义的属性名。,即某一检测项目的名称,是ID代码的文字解释。
- FLAG
属性操作标志(可以忽略)
- 当前值(value)
当前值是各ID项在硬盘运行时根据实测原始数据(Raw value)通过公式计算的结果,1到253之间。253意味着最好情况,1意味着最坏情况。计算公式由硬盘厂家自定。 硬盘出厂时各ID项目都有一个预设的最大正常值,也即出厂值,这个预设的依据及计算方法为硬盘厂家保密,不同型号的硬盘都不同,最大正常值通常为100或200或253,新硬盘刚开始使用时显示的当前值可以认为是预设的最大正常值(有些ID项如温度等除外)。随着使用损耗或出现错误,当前值会根据实测数据而不断刷新并逐渐减小。因此,当前值接近临界值就意味着硬盘寿命的减少,发生故障的可能性增大,所以当前值也是判定硬盘健康状态或推测寿命的依据之一。
- 最差值(Worst)
最差值是硬盘运行时各ID项曾出现过的最小的value。 最差值是对硬盘运行中某项数据变劣的峰值统计,该数值也会不断刷新。通常,最差值与当前值是相等的,如果最差值出现较大的波动(小于当前值),表明硬盘曾出现错误或曾经历过恶劣的工作环境(如温度)。
- 临界值(Threshold)
在报告硬盘FAILED状态前,WORST可以允许的最小值。
临界值是硬盘厂商指定的表示某一项目可靠性的门限值,也称阈值,它通过特定公式计算而得。如果某个参数的当前值接近了临界值,就意味着硬盘将变得不可靠,可能导致数据丢失或者硬盘故障。由于临界值是硬盘厂商根据自己产品特性而确定的,因此用厂商提供的专用检测软件往往会跟Windows下检测软件的检测结果有较大出入。
硬盘的每项SMART信息中都有一个临界值(阈值),不同硬盘的临界值是不同的,SMART针对各项的当前值、最差值和临界值的比较结果以及数据值进行分析后,提供硬盘当前的评估状态,也是我们直观判断硬盘健康状态的重要信息。根据SMART的规定,状态一般有正常、警告、故障或错误三种状态。
SMART判定这三个状态与SMART的 Pre-failure/advisory BIT(预测错误/发现位)参数的赋值密切相关,当Pre-failure/advisory BIT=0,并且当前值、最差值远大于临界值的情况下,为正常标志。当Pre-failure/advisory BIT=0,并且当前值、最差值大于但接近临界值时,为警告标志;当Pre-failure/advisory BIT=1,并且当前值、最差值小于临界值时,为故障或错误标志
- 原始值(RAW_VALUE)
制造商定义的原始值,从VALUE派生。
数据值是硬盘运行时各项参数的实测值,大部分SMART工具以十进制显示数据。 数据值代表的意义随参数而定,大致可以分为三类: 1)数据值并不直接反映硬盘状态,必须经过硬盘内置的计算公式换算成当前值才能得出结果; 2)数据值是直接累计的,如Start/Stop Count(启动/停止计数)的数据是50,即表示该硬盘从出厂到现在累计启停了50次; 3)有些参数的数据是即时数,如Temperature(温度)的数据值是44,表示硬盘的当前温度是44℃。 因此,有些参数直接查看数据也能大致了解硬盘目前的工作状态。
- TYPE
属性的类型(Pre-fail或Oldage)。Pre-fail类型的属性可被看成一个关键属性,表示参与磁盘的整体SMART健康评估(PASSED/FAILED)。如果任何Pre-fail类型的属性故障,那么可视为磁盘将要发生故障。另一方面,Oldage类型的属性可被看成一个非关键的属性(如正常的磁盘磨损),表示不会使磁盘本身发生故障。
- UPDATED
表示属性的更新频率。Offline代表磁盘上执行离线测试的时间。
- WHEN_FAILED
如果VALUE小于等于THRESH,会被设置成“FAILING_NOW”;如果WORST小于等于THRESH会被设置成“In_the_past”;如果都不是,会被设置成“-”。在“FAILING_NOW”情况下,需要尽快备份重要 文件,特别是属性是Pre-fail类型时。“In_the_past”代表属性已经故障了,但在运行测试的时候没问题。“-”代表这个属性从没故障过。
三、SMART参数详解
一般情况下,用户只要观察当前值、最差值和临界值的关系,并注意状态提示信息即可大致了解硬盘的健康状况。下面简单介绍各参数的含义,以红色标出的项目是寿命关键项,蓝色为固态硬盘(SSD)特有的项目。 在基于闪存的固态硬盘中,存储单元分为两类:SLC(Single Layer Cell,单层单元)和MLC(Multi-Level Cell,多层单元)。SLC成本高、容量小、但读写速度快,可靠性高,擦写次数可高达100000次,比MLC高10倍。而MLC虽容量大、成本低,但其性能大幅落后于SLC。为了保证MLC的寿命,控制芯片还要有智能磨损平衡技术算法,使每个存储单元的写入次数可以平均分摊,以达到100万小时的平均无故障时间。因此固态硬盘有许多SMART参数是机械硬盘所没有的,如存储单元的擦写次数、备用块统计等等,这些新增项大都由厂家自定义,有些尚无详细的解释,有些解释也未必准确,此处也只是仅供参考。下面凡未注明厂商的固态硬盘特有的项均为SandForce主控芯片特有的,其它厂商各自单独注明。
-
01(001)底层数据读取错误率 Raw Read Error Rate 数据为0或任意值,当前值应远大于与临界值。 底层数据读取错误率是磁头从磁盘表面读取数据时出现的错误,对某些硬盘来说,大于0的数据表明磁盘表面或者读写磁头发生问题,如介质损伤、磁头污染、磁头共振等等。不过对希捷硬盘来说,许多硬盘的这一项会有很大的数据量,这不代表有任何问题,主要是看当前值下降的程度。 在固态硬盘中,此项的数据值包含了可校正的错误与不可校正的RAISE错误(UECC+URAISE)。 注:RAISE(Redundant Array of Independent Silicon Elements)意为独立硅元素冗余阵列,是固态硬盘特有的一种冗余恢复技术,保证内部有类似RAID阵列的数据安全性。
-
02(002)磁盘读写通量性能 Throughput Performance 此参数表示硬盘的读写通量性能,数据值越大越好。当前值如果偏低或趋近临界值,表示硬盘存在严重的问题,但现在的硬盘通常显示数据值为0或根本不显示此项,一般在进行了人工脱机SMART测试后才会有数据量。
-
03(003)主轴起旋时间 Spin Up Time 主轴起旋时间就是主轴电机从启动至达到额定转速所用的时间,数据值直接显示时间,单位为毫秒或者秒,因此数据值越小越好。不过对于正常硬盘来说,这一项仅仅是一个参考值,硬盘每次的启动时间都不相同,某次启动的稍慢些也不表示就有问题。 硬盘的主轴电机从启动至达到额定转速大致需要4秒~15秒左右,过长的启动时间说明电机驱动电路或者轴承机构有问题。旦这一参数的数据值在某些型号的硬盘上总是为0,这就要看当前值和最差值来判断了。 对于固态硬盘来说,所有的数据都是保存在半导体集成电路中,没有主轴电机,所以这项没有意义,数据固定为0,当前值固定为100。
-
04(004)启停计数 Start/Stop Count 这一参数的数据是累计值,表示硬盘主轴电机启动/停止的次数,新硬盘通常只有几次,以后会逐渐增加。系统的某些功能如空闲时关闭硬盘等会使硬盘启动/停止的次数大为增加,在排除定时功能的影响下,过高的启动/停止次数(远大于通电次数0C)暗示硬盘电机及其驱动电路可能有问题。 这个参数的当前值是依据某种公式计算的结果,例如对希捷某硬盘来说临界值为20,当前值是通过公式“100-(启停计数/1024)”计算得出的。若新硬盘的启停计数为0,当前值为100-(0/1024)=100,随着启停次数的增加,该值不断下降,当启停次数达到81920次时,当前值为100-(81920/1024)=20,已达到临界值,表示从启停次数来看,该硬盘已达设计寿命,当然这只是个寿命参考值,并不具有确定的指标性。 这一项对于固态硬盘同样没有意义,数据固定为0,当前值固定为100。
-
05(005)重映射扇区计数 Reallocated Sectors Count/ 退役块计数 Retired Block Count 数据应为0,当前值应远大于临界值。 当硬盘的某扇区持续出现读/写/校验错误时,硬盘固件程序会将这个扇区的物理地址加入缺陷表(G-list),将该地址重新定向到预先保留的备用扇区并将其中的数据一并转移,这就称为重映射。执行重映射操作后的硬盘在Windows常规检测中是无法发现不良扇区的,因其地址已被指向备用扇区,这等于屏蔽了不良扇区。 这项参数的数据值直接表示已经被重映射扇区的数量,当前值则随着数据值的增加而持续下降。当发现此项的数据值不为零时,要密切注意其发展趋势,若能长期保持稳定,则硬盘还可以正常运行;若数据值不断上升,说明不良扇区不断增加,硬盘已处于不稳定状态,应当考虑更换了。如果当前值接近或已到达临界值(此时的数据值并不一定很大,因为不同硬盘保留的备用扇区数并不相同),表示缺陷表已满或备用扇区已用尽,已经失去了重映射功能,再出现不良扇区就会显现出来并直接导致数据丢失。 这一项不仅是硬盘的寿命关键参数,而且重映射扇区的数量也直接影响硬盘的性能,例如某些硬盘会出现数据量很大,但当前值下降不明显的情况,这种硬盘尽管还可正常运行,但也不宜继续使用。因为备用扇区都是位于磁盘尾部(靠近盘片轴心处),大量的使用备用扇区会使寻道时间增加,硬盘性能明显下降。 这个参数在机械硬盘上是非常敏感的,而对于固态硬盘来说同样具有重要意义。闪存的寿命是正态分布的,例如说MLC能写入一万次以上,实际上说的是写入一万次之前不会发生“批量损坏”,但某些单元可能写入几十次就损坏了。换言之,机械硬盘的盘片不会因读写而损坏,出现不良扇区大多与工艺质量相关,而闪存的读写次数则是有限的,因而损坏是正常的。所以固态硬盘在制造时也保留了一定的空间,当某个存储单元出现问题后即把损坏的部分隔离,用好的部分来顶替。这一替换方法和机械硬盘的扇区重映射是一个道理,只不过机械硬盘正常时极少有重映射操作,而对于固态硬盘是经常性的。 在固态硬盘中这一项的数据会随着使用而不断增长,只要增长的速度保持稳定就可以。通常情况下,数据值=100-(100×被替换块/必需块总数),因此也可以估算出硬盘的剩余寿命。 Intel固态硬盘型号的第十二个字母表示了两种规格,该字母为1表示第一代的50纳米技术的SSD,为2表示第二代的34纳米技术的SSD,如SSDSA2M160G2GN就表示是34nm的SSD。所以参数的查看也有两种情况: 50nm的SSD(一代)要看当前值。这个值初始是100,当出现替换块的时候这个值并不会立即变化,一直到已替换四个块时这个值变为1,之后每增加四个块当前值就+1。也就是100对应0~3个块,1对应4~7个块,2对应8~11个块…… 34nm的SSD(二代)直接查看数据值,数据值直接表示有多少个被替换的块。
-
06(006)读取通道余量 Read Channel Margin 这一项功能不明,现在的硬盘也不显示这一项。
-
07(007)寻道错误率 Seek Error Rate 数据应为0,当前值应远大于与临界值。 这一项表示磁头寻道时的错误率,有众多因素可导致寻道错误率上升,如磁头组件的机械系统、伺服电路有局部问题,盘片表面介质不良,硬盘温度过高等等。 通常此项的数据应为0,但对希捷硬盘来说,即使是新硬盘,这一项也可能有很大的数据量,这不代表有任何问题,还是要看当前值是否下降。
-
08(008)寻道性能 Seek Time Performance 此项表示硬盘寻道操作的平均性能(寻道速度),通常与前一项(寻道错误率)相关联。当前值持续下降标志着磁头组件、寻道电机或伺服电路出现问题,但现在许多硬盘并不显示这一项。
-
09(009)通电时间累计 Power-On Time Count (POH) 这个参数的含义一目了然,表示硬盘通电的时间,数据值直接累计了设备通电的时长,新硬盘当然应该接近0,但不同硬盘的计数单位有所不同,有以小时计数的,也有以分、秒甚至30秒为单位的,这由磁盘制造商来定义。 这一参数的临界值通常为0,当前值随着硬盘通电时间增加会逐渐下降,接近临界值表明硬盘已接近预计的设计寿命,当然这并不表明硬盘将出现故障或立即报废。参考磁盘制造商给出的该型号硬盘的MTBF(平均无故障时间)值,可以大致估计剩余寿命或故障概率。 对于固态硬盘,要注意“设备优先电源管理功能(device initiated power management,DIPM)”会影响这个统计:如果启用了DIPM,持续通电计数里就不包括睡眠时间;如果关闭了DIPM功能,那么活动、空闲和睡眠三种状态的时间都会被统计在内。
-
0A(010)主轴起旋重试次数 Spin up Retry Count 数据应为0,当前值应大于临界值。 主轴起旋重试次数的数据值就是主轴电机尝试重新启动的计数,即主轴电机启动后在规定的时间里未能成功达到额定转速而尝试再次启动的次数。数据量的增加表示电机驱动电路或是机械子系统出现问题,整机供电不足也会导致这一问题。
-
0B(011)磁头校准重试计数 Calibration Retry Count 数据应为0,当前值应远大于与临界值。 硬盘在温度发生变化时,机械部件(特别是盘片)会因热胀冷缩出现形变,因此需要执行磁头校准操作消除误差,有的硬盘还内置了磁头定时校准功能。这一项记录了需要再次校准(通常因上次校准失败)的次数。 这一项的数据量增加,表示电机驱动电路或是机械子系统出现问题,但有些型号的新硬盘也有一定的数据量,并不表示有问题,还要看当前值和最差值。
-
0C(012)通电周期计数 Power Cycle Count 通电周期计数的数据值表示了硬盘通电/断电的次数,即电源开关次数的累计,新硬盘通常只有几次。 这一项与启停计数(04)是有区别的,一般来说,硬盘通电/断电意味着计算机的开机与关机,所以经历一次开关机数据才会加1;而启停计数(04)表示硬盘主轴电机的启动/停止(硬盘在运行时可能多次启停,如系统进入休眠或被设置为空闲多少时间而关闭)。所以大多情况下这个通电/断电的次数会小于启停计数(04)的次数。 通常,硬盘设计的通电次数都很高,如至少5000次,因此这一计数只是寿命参考值,本身不具指标性。
-
0D(013)软件读取错误率 Soft Read Error Rate 软件读取错误率也称为可校正的读取误码率,就是报告给操作系统的未经校正的读取错误。数据值越低越好,过高则可能暗示盘片磁介质有问题。
-
AA(170)坏块增长计数 Grown Failing Block Count(Micron 镁光) 读写失败的块增长的总数。
-
AB(171)编程失败块计数 Program Fail Block Count Flash编程失败块的数量。
-
AC(172)擦写失败块计数 Erase Fail Block Count 擦写失败块的数量。
-
AD(173)磨损平衡操作次数(平均擦写次数) / Wear Leveling Count(Micron 镁光) 所有好块的平均擦写次数。 Flash芯片有写入次数限制,当使用FAT文件系统时,需要频繁地更新文件分配表。如果闪存的某些区域读写过于频繁,就会比其它区域磨损的更快,这将明显缩短整个硬盘的寿命(即便其它区域的擦写次数还远小于最大限制)。所以,如果让整个区域具有均匀的写入量,就可明显延长芯片寿命,这称为磨损均衡措施。
-
AE(174)意外失电计数 Unexpected Power Loss Count 硬盘自启用后发生意外断电事件的次数。
-
B1(177)磨损范围对比值 Wear Range Delta 磨损最重的块与磨损最轻的块的磨损百分比之差。
-
B4(180)未用的备用块计数 Unused Reserved Block Count Total(惠普) 固态硬盘会保留一些容量来准备替换损坏的存储单元,所以可用的预留空间数非常重要。这个参数的当前值表示的是尚未使用的预留的存储单元数量。
-
B5(181)编程失败计数 Program Fail Count 用4个字节显示已编程失败的次数,与(AB)参数相似。
-
B5(181)非4KB对齐访问数 Non-4k Aligned Access(Micron 镁光)
-
B6(182)擦写失败计数 Erase Fail Count 用4个字节显示硬盘自启用后块擦写失败的次数,与(AC)参数相似。
-
B7(183)串口降速错误计数 SATA Downshift Error Count 这一项表示了SATA接口速率错误下降的次数。通常硬盘与主板之间的兼容问题会导致SATA传输级别降级运行。
-
B8(184)I/O错误检测与校正 I/O Error Detection and Correction(IOEDC) “I/O错误检测与校正”是惠普公司专有的SMART IV技术的一部分,与其他制造商的I/O错误检测和校正架构一样,它记录了数据通过驱动器内部高速缓存RAM传输到主机时的奇偶校验错误数量。
-
B8(184)点到点错误检测计数 End to End Error Detection Count Intel第二代的34nm固态硬盘有点到点错误检测计数这一项。固态硬盘里有一个LBA(logical block addressing,逻辑块地址)记录,这一项显示了SSD内部逻辑块地址与真实物理地址间映射的出错次数。
-
B8(184)原始坏块数 Init Bad Block Count(Indilinx芯片) 硬盘出厂时已有的坏块数量。
-
B9(185)磁头稳定性 Head Stability(西部数据) 意义不明。
-
BA(186)感应运算振动检测 nduced Op-Vibration Detection(西部数据) 意义不明。
-
BB(187)无法校正的错误 Reported Uncorrectable Errors(希捷) 报告给操作系统的无法通过硬件ECC校正的错误。如果数据值不为零,就应该备份硬盘上的数据了。 报告给操作系统的在所有存取命令中出现的无法校正的RAISE(URAISE)错误。
-
BC(188)命令超时 Command Timeout 由于硬盘超时导致操作终止的次数。通常数据值应为0,如果远大于零,最有可能出现的是电源供电问题或者数据线氧化致使接触不良,也可能是硬盘出现严重问题。
-
BD(189)高飞写入 High Fly Writes 磁头飞行高度监视装置可以提高读写的可靠性,这一装置时刻监测磁头的飞行高度是否在正常范围来保证可靠的写入数据。如果磁头的飞行高度出现偏差,写入操作就会停止,然后尝试重新写入或者换一个位置写入。这种持续的监测过程提高了写入数据的可靠性,同时也降低了读取错误率。这一项的数据值就统计了写入时磁头飞行高度出现偏差的次数。
-
BD(189)出厂坏块计数 Factory Bad Block Count(Micron 镁光芯片)
-
BE(190)气流温度 Airflow Temperature 这一项表示的是硬盘内部盘片表面的气流温度。在希捷公司的某些硬盘中,当前值=(100-当前温度),因此气流温度越高,当前值就越低,最差值则是当前值曾经到达过的最低点,临界值由制造商定义的最高允许温度来确定,而数据值不具实际意义。许多硬盘也没有这一项参数。
-
BF(191)冲击错误率 G-sense error rate 这一项的数据值记录了硬盘受到机械冲击导致出错的频度。
-
C0(192)断电返回计数 Power-Off Retract Count 当计算机关机或意外断电时,硬盘的磁头都要返回停靠区,不能停留在盘片的数据区里。正常关机时电源会给硬盘一个通知,即Standby Immediate,就是说主机要求将缓存数据写入硬盘,然后就准备关机断电了(休眠、待机也是如此);意外断电则表示硬盘在未收到关机通知时就失电,此时磁头会自动复位,迅速离开盘片。 这个参数的数据值累计了磁头返回的次数。但要注意这个参数对某些硬盘来说仅记录意外断电时磁头的返回动作;而某些硬盘记录了所有(包括休眠、待机,但不包括关机时)的磁头返回动作;还有些硬盘这一项没有记录。因此这一参数的数据值在某些硬盘上持续为0或稍大于0,但在另外的硬盘上则会大于通电周期计数(0C)或启停计数(04)的数据。在一些新型节能硬盘中,这一参数的数据量还与硬盘的节能设计相关,可能会远大于通电周期计数(0C)或启停计数(04)的数据,但又远小于磁头加载/卸载计数(C1)的数据量。 对于固态硬盘来说,虽然没有磁头的加载/卸载操作,但这一项的数据量仍然代表了不安全关机,即发生意外断电的次数。
-
C1(193)磁头加载/卸载计数 Load/Unload Cycle Count 对于过去的硬盘来说,盘片停止旋转时磁头臂停靠于盘片中心轴处的停泊区,磁头与盘片接触,只有当盘片旋转到一定转速时,磁头才开始漂浮于盘片之上并开始向外侧移动至数据区。这使得磁头在硬盘启停时都与盘片发生摩擦,虽然盘片的停泊区不存储数据,但无疑启停一个循环,就使磁头经历两次磨损。所以对以前的硬盘来说,磁头起降(加载/卸载)次数是一项重要的寿命关键参数。 而在现代硬盘中,平时磁头臂是停靠于盘片之外的一个专门设计的停靠架上,远离盘片。只有当盘片旋转达到额定转速后,磁头臂才开始向内(盘片轴心)转动使磁头移至盘片区域(加载),磁头臂向外转动返回至停靠架即卸载。这样就彻底杜绝了硬盘启停时磁头与盘片接触的现象,西部数据公司将其称为“斜坡加载技术”。由于磁头在加载/卸载过程中始终不与盘片接触,不存在磁头的磨损,使得这一参数的重要性已经大大下降。 这个参数的数据值就是磁头执行加载/卸载操作的累计次数。从原理上讲,这个加载/卸载次数应当与硬盘的启停次数相当,但对于笔记本内置硬盘以及台式机新型节能硬盘来说,这一项的数据量会很大。这是因为磁头臂组件设计有一个固定的返回力矩,保证在意外断电时磁头能靠弹簧力自动离开盘片半径范围,迅速返回停靠架。所以要让硬盘运行时磁头保持在盘片的半径之内,就要使磁头臂驱动电机(寻道电机)持续通以电流。而让磁头臂在硬盘空闲几分钟后就立即执行卸载动作,返回到停靠架上,既有利于节能,又降低了硬盘受外力冲击导致磁头与盘片接触的概率。虽然再次加载会增加一点寻道时间,但毕竟弊大于利,所以在这类硬盘中磁头的加载/卸载次数会远远大于通电周期计数(0C)或启停计数(04)的数据量。不过这种加载/卸载方式已经没有了磁头与盘片的接触,所以设计值也已大大增加,通常笔记本内置硬盘的磁头加载/卸载额定值在30~60万次,而台式机新型节能硬盘的磁头加载/卸载设计值可达一百万次。
-
C2(194)温度 Temperature 温度的数据值直接表示了硬盘内部的当前温度。硬盘运行时最好不要超过45℃,温度过高虽不会导致数据丢失,但引起的机械变形会导致寻道与读写错误率上升,降低硬盘性能。硬盘的最高允许运行温度可查看硬盘厂商给出的数据,一般不会超过60℃。 不同厂家对温度参数的当前值、最差值和临界值有不同的表示方法:希捷公司某些硬盘的当前值就是实际温度(摄氏)值,最差值则是曾经达到过的最高温度,临界值不具意义;而西部数据公司一些硬盘的最差值是温度上升到某值后的时间函数,每次升温后的持续时间都将导致最差值逐渐下降,当前值则与当前温度成反比,即当前温度越高,当前值越低,随实际温度波动。
-
C3(195)硬件ECC校正 Hardware ECC Recovered ECC(Error Correcting Code)的意思是“错误检查和纠正”,这个技术能够容许错误,并可以将错误更正,使读写操作得以持续进行,不致因错误而中断。这一项的数据值记录了磁头在盘片上读写时通过ECC技术校正错误的次数,不过许多硬盘有其制造商特定的数据结构,因此数据量的大小并不能直接说明问题。
-
C3(195)实时无法校正错误计数 On the fly ECC Uncorrectable Error Count 这一参数记录了无法校正(UECC)的错误数量。
-
C3(195)编程错误块计数 Program Failure block Count(Indilinx芯片)
-
C4(196)重映射事件计数 Reallocetion Events Count 数据应为0,当前值应远大于临界值。 这个参数的数据值记录了将重映射扇区的数据转移到备用扇区的尝试次数,是重映射操作的累计值,成功的转移和不成功的转移都会被计数。因此这一参数与重映射扇区计数(05)相似,都是反映硬盘已经存在不良扇区。
-
C4(196)擦除错误块计数 Erase Failure block Count(Indilinx芯片) 在固态硬盘中,这一参数记录了被重映射的块编程失败的数量。
-
C5(197)当前待映射扇区计数 Current Pending Sector Count 数据应为0,当前值应远大于临界值。 这个参数的数据表示了“不稳定的”扇区数,即等待被映射的扇区(也称“被挂起的扇区”)数量。如果不稳定的扇区随后被读写成功,该扇区就不再列入等待范围,数据值就会下降。 仅仅读取时出错的扇区并不会导致重映射,只是被列入“等待”,也许以后读取就没有问题,所以只有在写入失败时才会发生重映射。下次对该扇区写入时如果继续出错,就会产生一次重映射操作,此时重映射扇区计数(05)与重映射事件计数(C4)的数据值增加,此参数的数据值下降。
-
C5(197)读取错误块计数(不可修复错误)Read Failure block Count(Indilinx芯片)
-
C6(198)脱机无法校正的扇区计数 Offline Uncorrectable Sector Count 数据应为0,当前值应远大于临界值。 这个参数的数据累计了读写扇区时发生的无法校正的错误总数。数据值上升表明盘片表面介质或机械子系统出现问题,有些扇区肯定已经不能读取,如果有文件正在使用这些扇区,操作系统会返回读盘错误的信息。下一次写操作时会对该扇区执行重映射。
-
C6(198)总读取页数 Total Count of Read Sectors(Indilinx芯片)
-
C7(199)Ultra ATA访问校验错误率 Ultra ATA CRC Error Rate 这个参数的数据值累计了通过接口循环冗余校验(Interface Cyclic Redundancy Check,ICRC)发现的数据线传输错误的次数。如果数据值不为0且持续增长,表示硬盘控制器→数据线→硬盘接口出现错误,劣质的数据线、接口接触不良都可能导致此现象。由于这一项的数据值不会复零,所以某些新硬盘也会出现一定的数据量,只要更换数据线后数据值不再继续增长,即表示问题已得到解决。
-
C7(199)总写入页数 Total Count of Write Sectors(Indilinx芯片)
- C8(200)写入错误率 Write Error Rate / 多区域错误率 Multi-Zone Error Rate(西部数据) 数据应为0,当前值应远大于临界值。 这个参数的数据累计了向扇区写入数据时出现错误的总数。有的新硬盘也会有一定的数据量,若数据值持续快速升高(当前值偏低),表示盘片、磁头组件可能有问题。
-
C8(200)总读取指令数 Total Count of Read Command(Indilinx芯片)
- C9(201)脱道错误率 Off Track Error Rate / 逻辑读取错误率 Soft Read Error Rate 数据值累积了读取时脱轨的错误数量,如果数据值不为0,最好备份硬盘上的资料。
- C9(201)TA Counter Detected(意义不明)
-
C9(201)写入指令总数 Total Count of Write Command(Indilinx芯片)
- CA(202)数据地址标记错误 Data Address Mark errors 此项的数据值越低越好(或者由制造商定义)。
- CA(202)TA Counter Increased(意义不明)
- CA(202)剩余寿命 Percentage Of The Rated Lifetime Used(Micron 镁光芯片) 当前值从100开始下降至0,表示所有块的擦写余量统计。计算方法是以MLC擦写次数除以50,SLC擦写次数除以1000,结果取整数,将其与100的差值作为当前值(MLC预计擦写次数为5000,SLC预计擦写次数为100000)。
-
CA(202)闪存总错误bit数 Total Count of error bits from flash(Indilinx芯片)
- CB(203)软件ECC错误数 Run Out Cancel 错误检查和纠正(ECC)出错的频度。
-
CB(203)校正bit错误的总读取页数 Total Count of Read Sectors with correct bits error(Indilinx芯片)
- CC(204)软件ECC校正 Soft ECC Correction 通过软件ECC纠正错误的计数。
-
CC(204)坏块满标志 Bad Block Full Flag(Indilinx芯片)
- CD(205)热骚动错误率 Thermal Asperity Rate (TAR) 由超温导致的错误。数据值应为0。
-
CD(205)最大可编程/擦除次数 Max P/E Count(Indilinx芯片)
- CE(206)磁头飞行高度 Flying Height 磁头距离盘片表面的垂直距离。高度过低则增加了磁头与盘片接触导致损坏的可能性;高度偏高则增大了读写错误率。不过准确地说,硬盘中并没有任何装置可以直接测出磁头的飞行高度,制造商也只是根据磁头读取的信号强度来推算磁头飞行高度。
- CE(206)底层数据写入出错率 Write Error Rate
-
CE(206)最小擦写次数 Erase Count Min(Indilinx芯片)
- CF(207)主轴过电流 Spin High Current 数据值记录了主轴电机运行时出现浪涌电流的次数,数据量的增加意味着轴承或电机可能有问题。
-
CF(207)最大擦写次数 Erase Count Max(Indilinx芯片)
- D0(208)主轴电机重启次数 Spin Buzz 数据值记录了主轴电机反复尝试启动的次数,这通常是由于电源供电不足引起的。
-
D0(208)平均擦写次数Erase Count Average(Indilinx芯片)
- D1(209)脱机寻道性能 Offline Seek Performance 这一项表示驱动器在脱机状态下的寻道性能,通常用于工厂内部测试。
-
D1(209)剩余寿命百分比 Remaining Life %(Indilinx芯片)
- D2(210)斜坡加载值 Ramp Load Value 这一项仅见于几年前迈拓制造的部分硬盘。通常数据值为0,意义不明。
-
D2(210)坏块管理错误日志 BBM Error Log(Indilinx芯片)
- D3(211)写入时振动 Vibration During Write 写入数据时受到受到外部振动的记录。
-
D3(211)SATA主机接口CRC写入错误计数 SATA Error Count CRC (Write)(Indilinx芯片)
- D4(212)写入时冲击 Shock During Write 写入数据时受到受到外部机械冲击的记录。
-
D4(212)SATA主机接口读取错误计数 SATA Error Count Count CRC (Read)(Indilinx芯片)
-
DC(220)盘片偏移量 Disk Shift 硬盘中的盘片相对主轴的偏移量(通常是受外力冲击或温度变化所致),单位未知,数据值越小越好。
-
DD(221)冲击错误率 G-sense error rate 与(BF)相同,数据值记录了硬盘受到外部机械冲击或振动导致出错的频度。
-
DE(222)磁头寻道时间累计 Loaded Hours 磁头臂组件运行的小时数,即寻道电机运行时间累计。
-
DF(223)磁头加载/卸载重试计数 Load/Unload Retry Count 这一项与(C1)项类似,数据值累积了磁头尝试重新加载/卸载的次数。
-
E0(224)磁头阻力 Load Friction 磁头工作时受到的机械部件的阻力。
-
E1(225)主机写入数据量 Host Writes 由于闪存的擦写次数是有限的,所以这项是固态硬盘特有的统计。Intel的SSD是每当向硬盘写入了65536个扇区,这一项的数据就+1。如果用HDTune等软件查看SMART时可以自己计算,Intel SSD Toolbox已经为你算好了,直接就显示了曾向SSD中写入过的数据量。
-
E2(226)磁头加载时间累计 Load ‘In’-time 磁头组件运行时间的累积数,即磁头臂不在停靠区的时间,与(DE)项相似。
-
E3(227)扭矩放大计数 Torque Amplification Count 主轴电机试图提高扭矩来补偿盘片转速变化的次数。当主轴轴承存在问题时,主轴电机会尝试增加驱动力使盘片稳定旋转。这个参数的当前值下降,说明硬盘的机械子系统出现了严重的问题。
-
E4(228)断电返回计数 Power-Off Retract Cycle 数据值累计了磁头因设备意外断电而自动返回的次数,与(C0)项相似。
-
E6(230)GMR磁头振幅 GMR Head Amplitude 磁头“抖动”,即正向/反向往复运动的距离。
- E7(231)温度 Temperature 温度的数据值直接表示了硬盘内部的当前温度,与(C2)项相同。
-
E7(231)剩余寿命 SSD Life Left 剩余寿命是基于P/E周期与可用的备用块作出的预测。新硬盘为100;10表示PE周期已到设计值,但尚有足够的保留块;0表示保留块不足,硬盘将处于只读方式以便备份数据。
- E8(232)寿命余量 Endurance Remaining 寿命余量是指硬盘已擦写次数与设计最大可擦写次数的百分比,与(CA)项相似。
-
E8(232)预留空间剩余量 Available Reserved Space(Intel芯片) 对于Intel的SSD来说,前边05项提到会保留一些容量来准备替换损坏的存储单元,所以可用的预留空间数非常重要。当保留的空间用尽,再出现损坏的单元就将出现数据丢失,这个SSD的寿命就结束了。所以仅看05项意义并不大,这一项才最重要。这项参数可以看当前值,新的SSD里所有的预留空间都在,所以是100。随着预留空间的消耗,当前值将不断下降,减小到接近临界值(一般是10)时,就说明只剩下10%的预留空间了,SSD的寿命将要结束。这个与(B4)项相似。
- E9(233)通电时间累计 Power-On Hours 对于普通硬盘来说,这一项与(09)相同。
-
E9(233)介质磨耗指数 Media Wareout Indicator(Intel芯片) 由于固态硬盘的擦写次数是有限的,当到达一定次数的时候,就会出现大量的单元同时损坏,这时候预留空间也顶不住了,所以这项参数实际上表示的是硬盘设计寿命。Intel的SSD要看当前值,随着NAND的平均擦写次数从0增长到最大的设计值,这一参数的当前值从开始的100逐渐下降至1为止。这表示SSD的设计寿命已经终结。当然到达设计寿命也不一定意味着SSD就立即报废,这与闪存芯片的品质有着很大的关系。 注:Total Erase Count全擦写计数是指固态硬盘中所有块的擦写次数的总和,不同规格的NAND芯片以及不同容量的SSD,其最大全擦写次数均有所不同。
-
F0(240)磁头飞行时间 Head Flying Hours / 传输错误率 Transfer Error Rate(富士通) 磁头位于工作位置的时间。 富士通硬盘表示在数据传输时连接被重置的次数。
- F1(241)LBA写入总数 Total LBAs Written LBA写入数的累计。
-
F1(241)写入剩余寿命 Lifetime Writes from Host 自硬盘启用后主机向硬盘写入的数据总量,以4个字节表示,每写入64GB字节作为一个单位。
- F2(242)LBA读取总数 Total LBAs Read LBA读取数的累计。某些SMART读取工具会显示负的数据值,是因为采用了48位LBA,而不是32位LBA。
-
F2(242)读取剩余寿命 Lifetime Reads from Host 自硬盘启用后主机从硬盘读取的数据总量,以4个字节表示,每读取64GB字节作为一个单位。
-
FA(250)读取错误重试率 Read Error Retry Rate 从磁盘上读取时出错的次数。
- FE(254)自由坠落保护 Free Fall Protection 现在有些笔记本硬盘具有自由坠落保护功能,当硬盘内置的加速度探测装置检测到硬盘位移时,会立即停止读写操作,将磁头臂复位。这个措施防止了磁头与盘片之间发生摩擦撞击,提高了硬盘的抗震性能。这个参数的数据里记录了这一保护装置动作的次数。