
学习整理:梯度下降(Gradient Descent)
参考链接:Intro to optimization in deep learning: Gradient Descent
概念
只有2个权值的情况下,理想的损失函数模型如下:
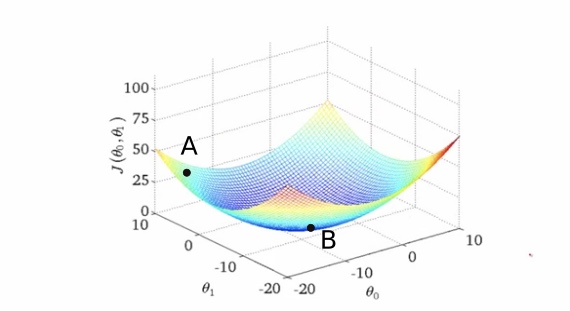
其中B点是损失值最小点,A点是出发点,通过更新权值向B点出发。
A点最快的方向是就是其切线方向(2维可以用切平面表示),可以利用导数求出。沿着切线下降方向移动,得到A点的梯度。反复求取梯度,最后到达最小值,如下图:
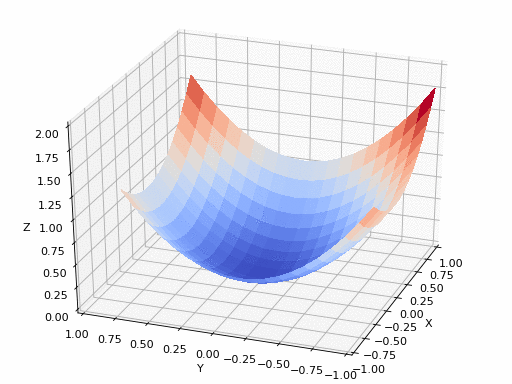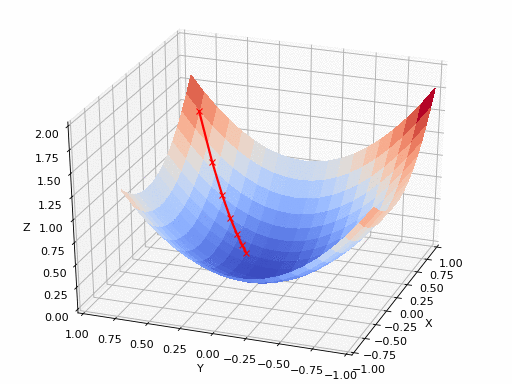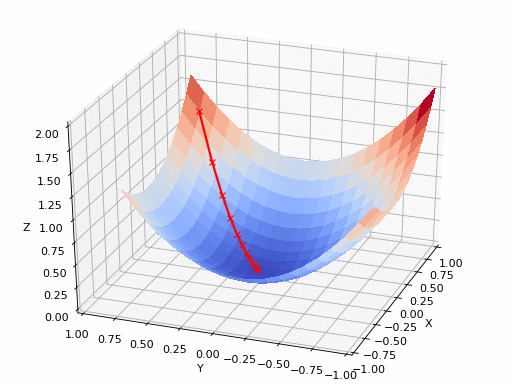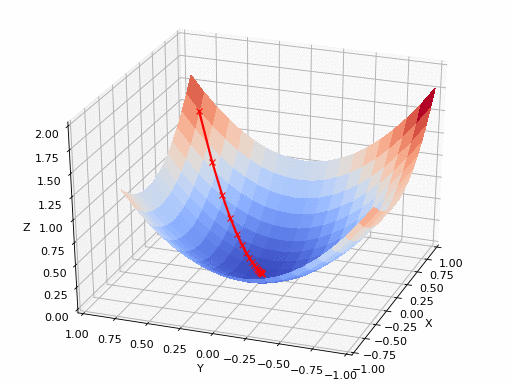
下降的幅度大小,即学习率。需要适当选取学习率,过小则移动太慢且容易陷入局部最小点;过大则容易出现在最小点周围盘旋,如下图:
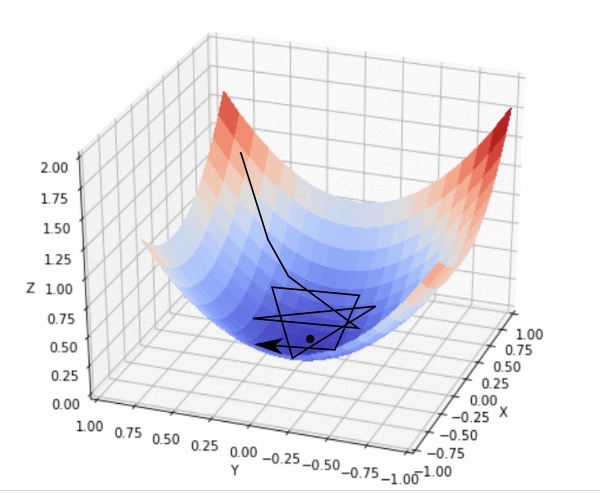
挑战
实际上的损失函数模型如下:
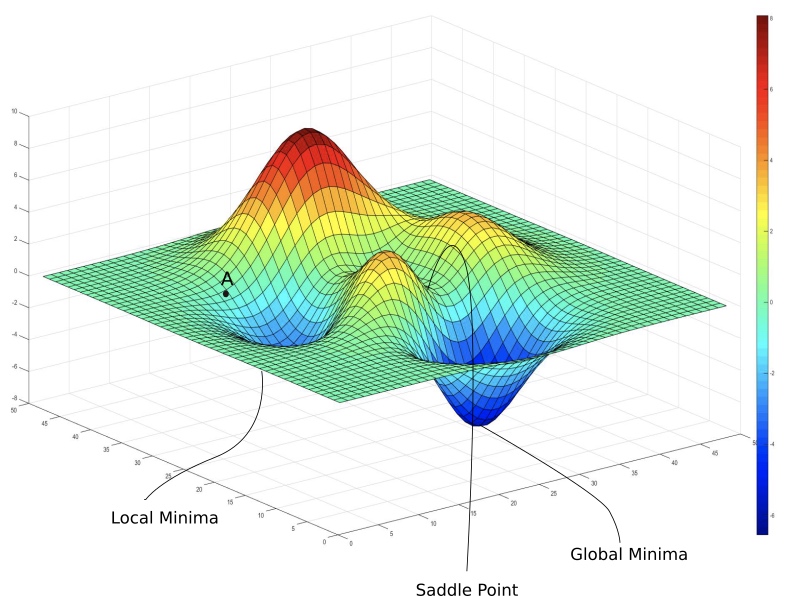
- 局部最小值。
- 鞍点。在某个权值维度是最小值,在另一个权值维度是最大值。
优化
-
正视局部最小值。可能并没有那么糟糕。
-
调整学习率。随机加权平均方案如下:
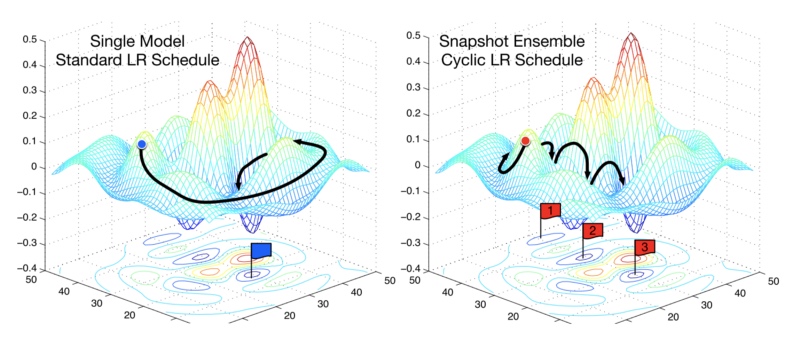
评论