
BERT
概述
BERT: Bidirectional Encoder Representation from Transformers
论文地址[2019]:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
对应github代码:github-bert
BERT分为 两个阶段:
Pre-training:利用无标记语料预训练模型Fine-tuning: 使用预训练的模型,对已经标记的语料根据实际的任务进行训练
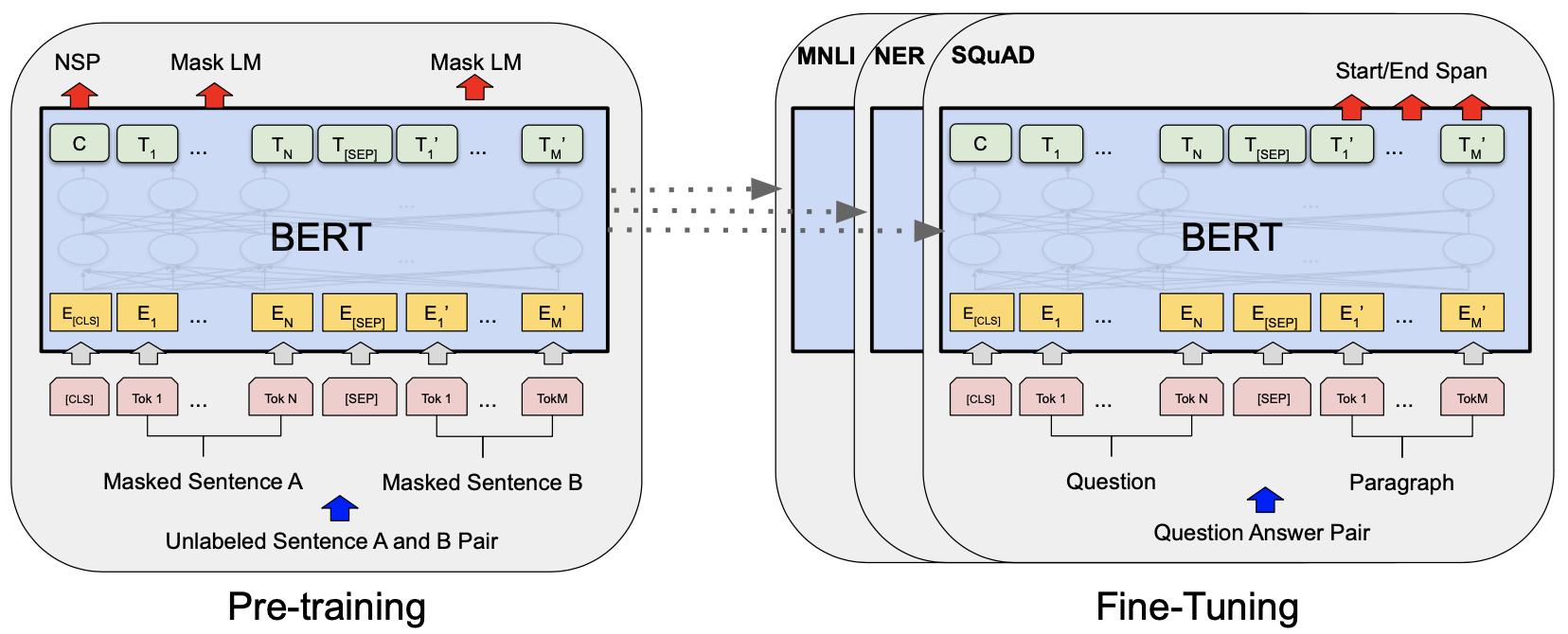
特征
预训练,使用Mask LM与NSP同时进行Masked language model,随机选取15%,其中80%概率被mask,10%概率被替换,10%概率不变,输出层得到mask位置的词的概率大小next sentence prediction,判断两句是否是上下文关系
双向Transformer,使输入的所有词包括词序互相融合深度,基础模型12层Transformer,Large模型24层。以下L表示层数,H表示hidden_size,A表示Heads数量:- Base:L = 12,H= 768,A = 12,Total Param = 110MB
- Large:L = 24,H= 1024,A = 16,Total Param = 340MB
Embeddings
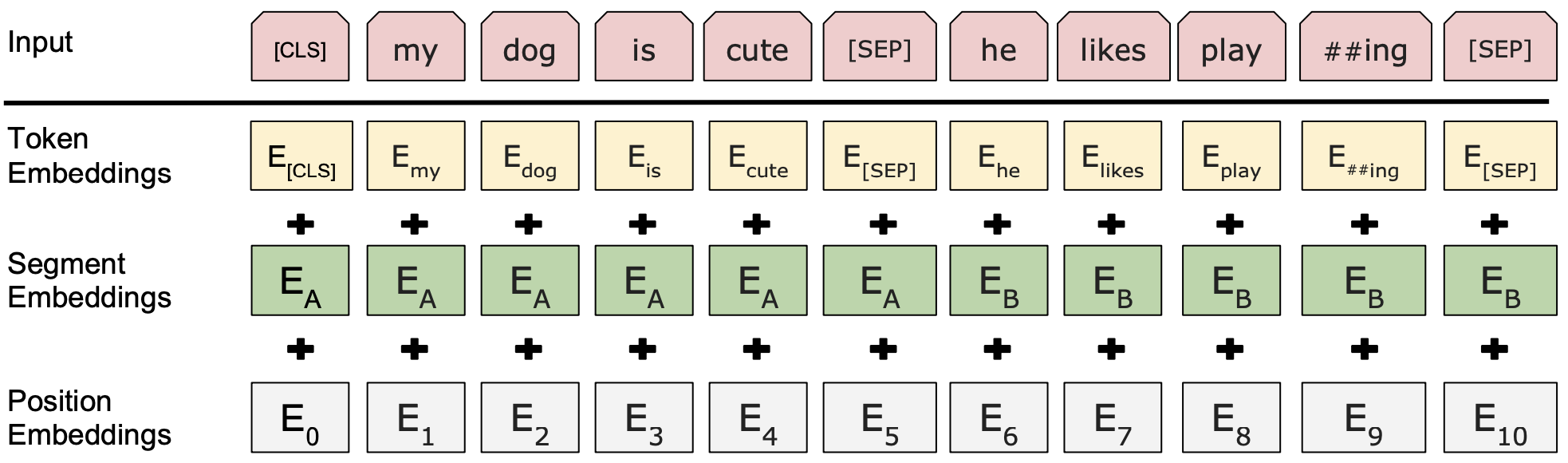
Token Embeddings,使用WordPiece模型创建,另外句子起始位置用[CLS],句子间隔用[SEP]Segment Embeddings,句子顺序Position Embeddings,词顺序
模型架构
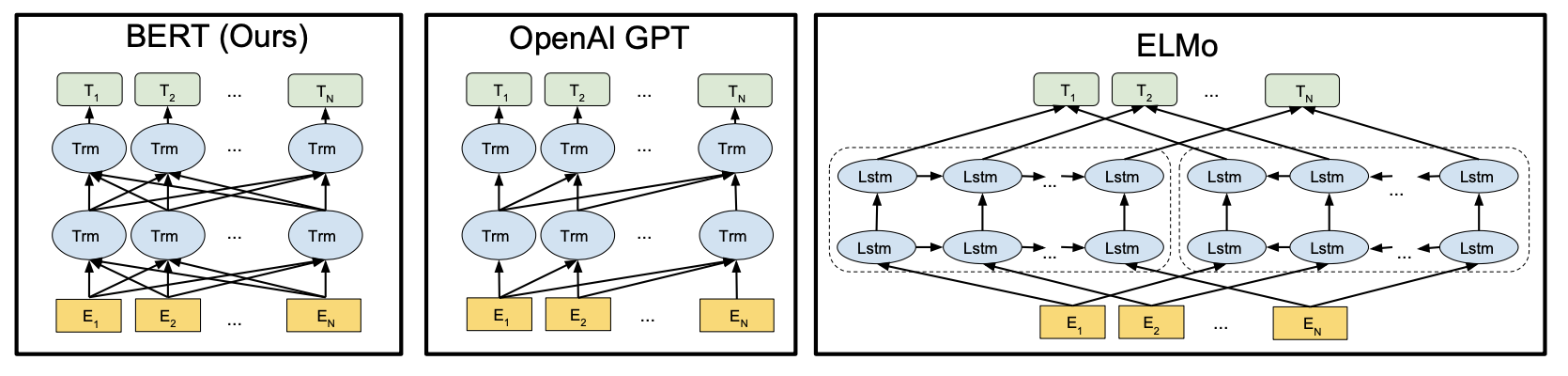
BERT采用双向transformerOpenAI GPT采用从左到右的的单向transformerELMo双向LSTM
参数
以Bert-base为例,词数为30522,seq_length是512,每个词向量长度为768(也就是hidden_size)
单batch输入为[seq_length]
Embedding
- input embedding:
[30522, 768]=> 23,440,896 - token embedding:
[2, 768]=> 1,536 - position embedding:
[512, 768]=> 393,216 - LayerNorm:
[768], [768]=> 1,536 - total: 23,837,184
Transformer * 12
- QKV FC:
3 * ([768, 768], [768])= 1,771,776 - output FC:
[768, 768], [768]= 590,592 - output LayerNorm:
[768], [768]= 1,536 - FeedForword1:
[768, 3072], [3072]= 2,362,368 - FeedForword2:
[3072, 768], [768]= 2,360,064 - FF LayerNorm:
[768], [768]= 1,536 - total: 12 * 7087872 = 85,054,464
Pooler
- dense:
[768, 768] + [768]= 590,592
Total
109,482,240
评论