
YOLO网络
概述
官网:YOLO: Real-Time Object Detection
论文地址:YOLO v1 2016 、YOLO v2 2017、YOLO v3 2018、YOLO v4 2020、YOLO v5 待更新
YOLO v1
模型结构
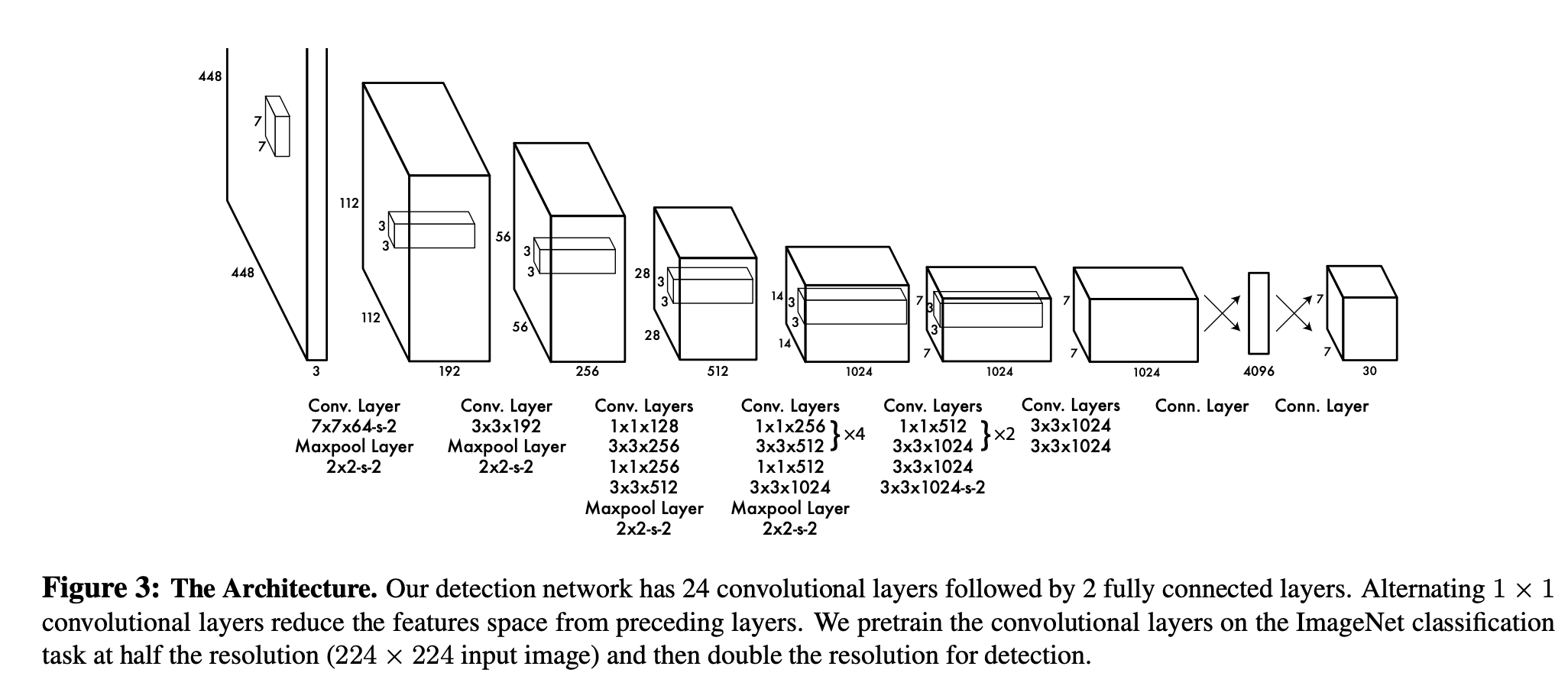
模型结构非常简单,24个卷积层(类似VGG16)部分复杂提取特征,2个全连接层负责预测。
其中激活函数为Leaky Relu,系数0.1。
过程如下:
- 输入为[1, 3, 448, 448],经过中间卷积层,得到输出为[1, 512, 7, 7];
- [1, 512, 7, 7]=>[1, 25088],做全连接[25088, 4096](此处参数量非常庞大), 得到[1, 4096];
- [1, 4096],做全连接[4096, 1470](此处参数量非常庞大),得到[1, 1470]
- [1, 1470] => [1, 7, 7, 30]
输出格式
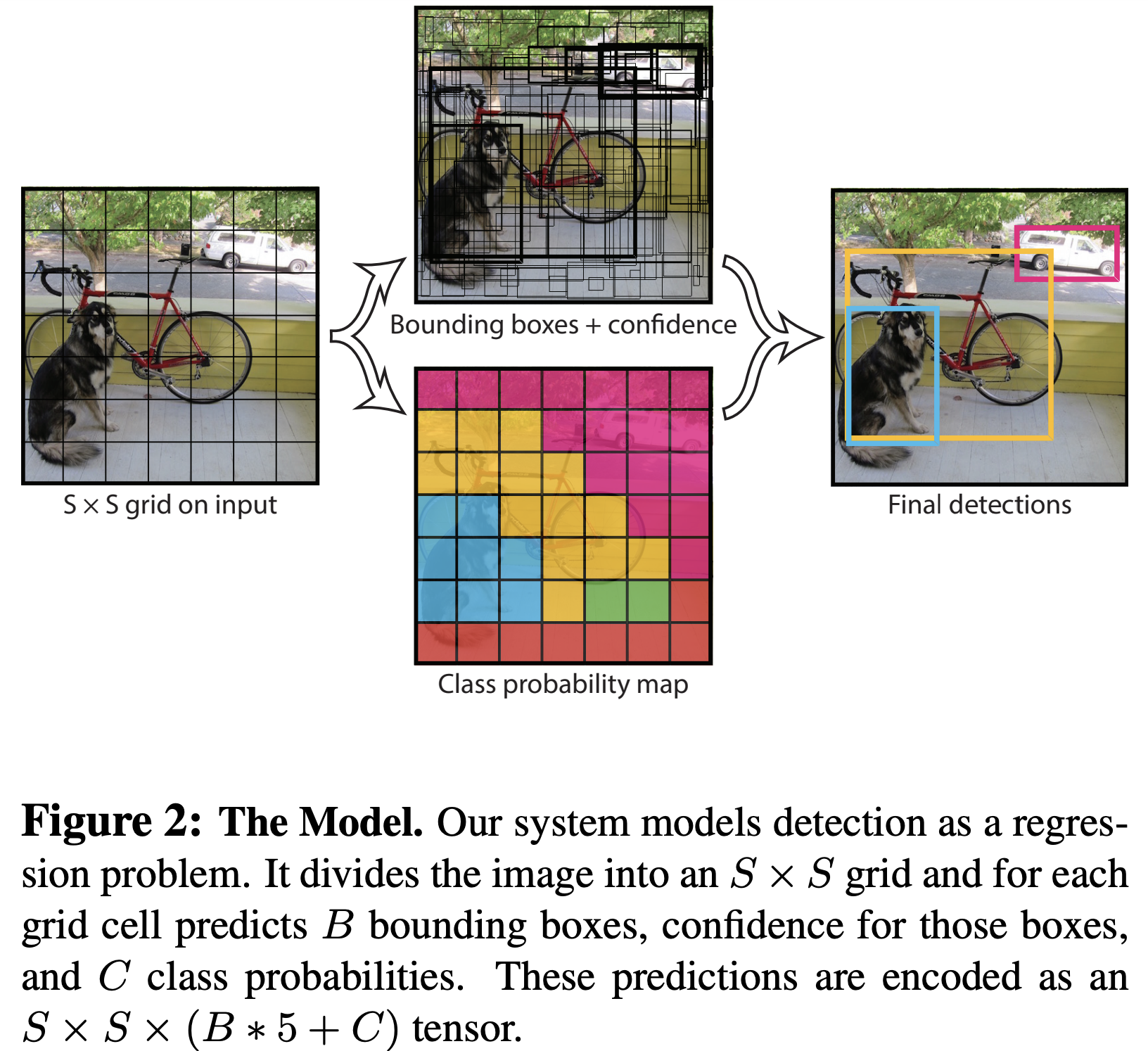
- 对原图SxS个中心点检测,这里S对应7
- B为检测box数量,这里B为2
- 每个box坐标表示为$ [x_{center}, y_{center}, w_{normalize}, h_{normalize}] $,加上一个检测的confidence(置信度)。
- C为类别,one-hot vector形式,这里为20
坐标转换
令i,j为格子位置,在[S,S]范围内遍历,则有:
$ x_{normalize} = \frac{x_{center} + i}{S} $
$ y_{normalize} = \frac{y_{center} + j}{S} $
这样就得到了归一化的坐标,再乘以原始图片的宽高,得到原始图片上的坐标
参考代码
特点
- 通过卷积+全连接,直接推导出位置和类别,是yolo网络的主要特点
- 最后两层全连接参数量很大,可以继续优化
YOLO v2
模型结构
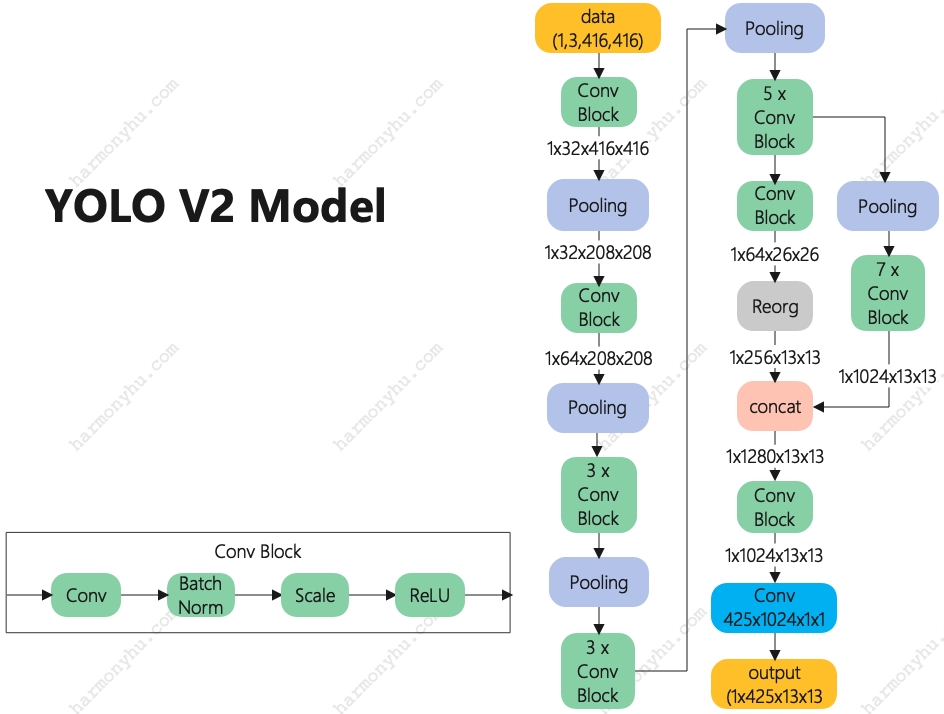
说明:
- 模型结构依然非常简单,相对YOLO v1最主要是的将两个全连接改成了卷积实现
- 输出为1x425x13x13,也可以permute成1x13x13x425来对比看待
- 其中reorg为重组层,将平面数据重组到深度上
输出格式
- 这里S为13,将原图划分为13x13个中心点检测
- 425 = 5个先验框 * (坐标4 + 置信度1 + 类型80),坐标表示为$ [t_x, t_y, t_w, t_h] $,置信度表示为$ t_o $
- 最终置信度为 $confidence = sigmoid(t_o) $,类型得分为$ class_{scole} =softmax(class{[0-79]}) $
坐标转换
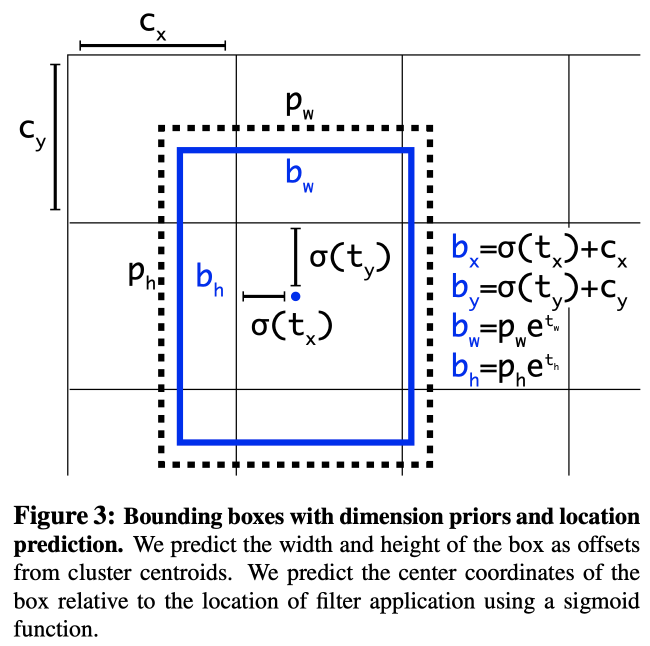
图中虚线部分是anchor框,根据kmeans算法提前得到。本模型中5个anchor框宽高分别为:[0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828]
令$ [c_x, c_y] $为格子位置,在[S, S]范围内遍历,则有:
$ b_x = sigmoid(t_x) + c_x $
$ b_y = sigmoid(t_y) + c_y $
$ b_w = p_w * e^{t_w} $
$ b_h = p_h * e^{t_h} $
$ box_{normalize} = [b_x, b_y, b_w, b_h] / S $
参考代码
特点
- 改进坐标置信度换算方式,使模型更容易学习,预测更稳定
- 改进模型结构,尤其是用卷积替换YOLO的2个全连接,大幅减少训练参数
YOLO v3
模型结构
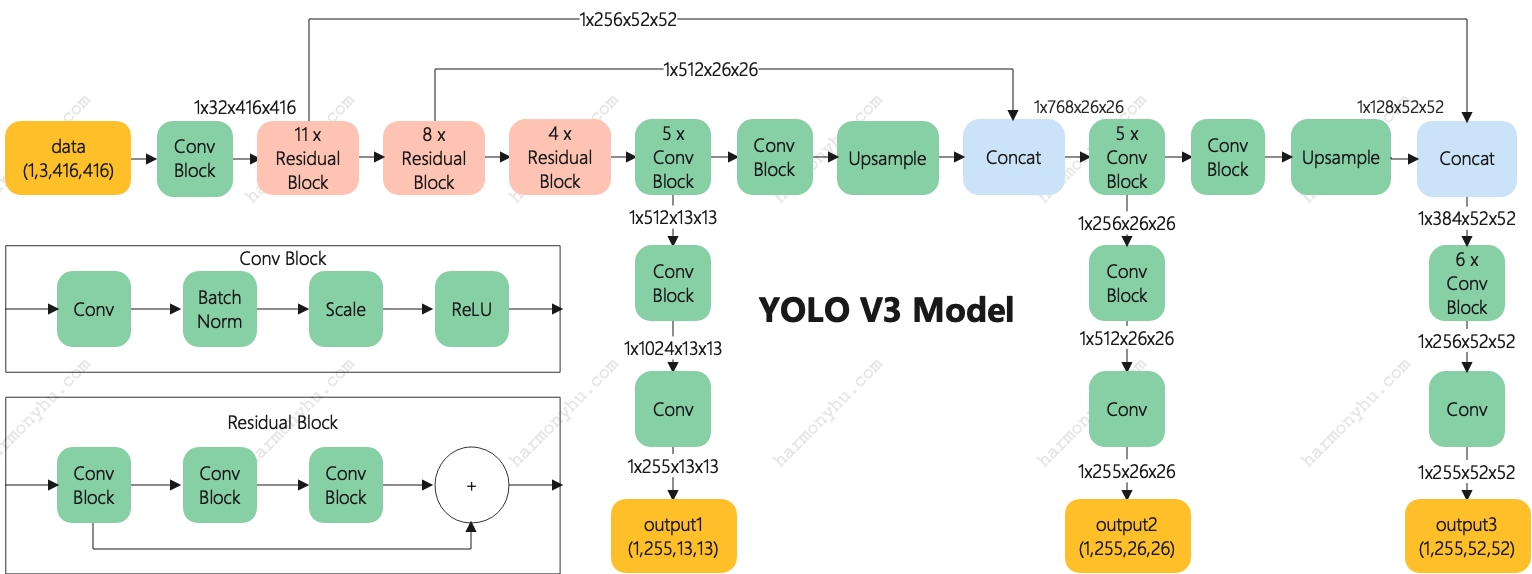
在YOLO V2基础上做了这几点改进:
- 使用残差模块做backbone
- 使用3种尺度:13x13、26x26、52x52
- 直接使用卷积stride=2达到池化效果,去掉pooling层
输出格式
与yolo v2相比,只有这几点不同:
-
255 = 3个先验框 * (坐标4 + 置信度1 + 类型80)
-
3个先验框的anchor分别为
[12, 16, 19, 36, 40, 28],[36, 75, 76, 55, 72, 146],[142, 110, 192, 243, 459, 401],对应output3/output2/output1 -
由于有3种尺度,为了统一anchor定义,anchor尺寸是输入尺寸;yolo v2是经过S等分后的尺寸。w/h计算如下:
$ w_{normalize} = \frac{p_w * e^{t_w}}{input_w} $,$ h_{normalize} = \frac{p_h * e^{t_h}}{input_h} $
参考代码
特点
- 使用残差模块做backbone
- 支持多种尺度
YOLO v4
模型结构
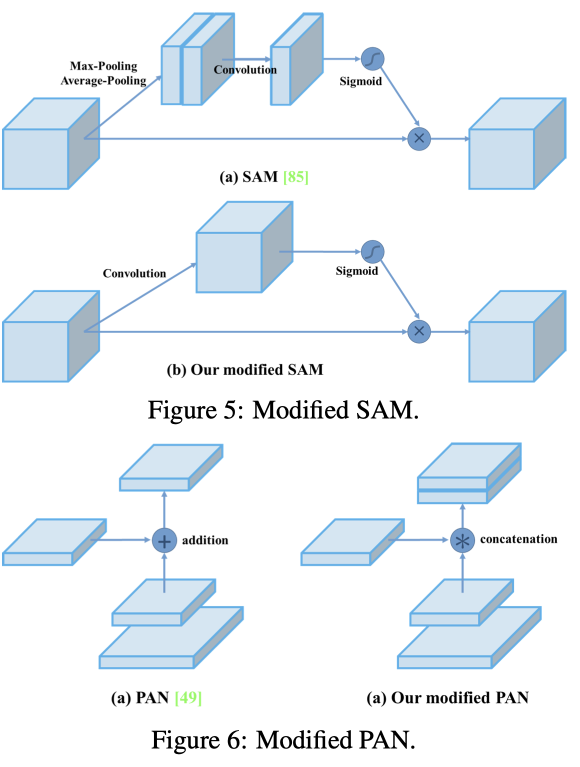
- 在yolo v3基础上进行技巧小改进,图略
- backbone中的激活函数由leaky relu替换成Mish
- 继续使用残差,部分残差将Add操作替换成Concat操作(Modified PAN);改进attention,使其更细粒度(Modified SAM)
评论